
코딩 자율학습 잔재미코딩의 파이썬 데이터 분석 입문 - 예스24
핵심만 쏙쏙! 반복 학습으로 데이터 인재로 거듭나기이 책은 데이터 분석을 체계적으로 익히려는 분과 파이썬을 배웠지만 다음 단계로 무엇을 해야 할지 고민인 분을 위한 책이다. 파이썬 데이
www.yes24.com
|
2주차
|
6일
|
7일
|
8일
|
9일
|
10일
|
|
목차
|
6장 데이터 전처리
6.1 결측치 처리하기
|
6장 데이터 전처리
6.2 데이터 타입 변환하기
6.3 데이터 재구성하기
|
6장 데이터 전처리
6.4 데이터 정제하기
6.5 데이터 병합하기
|
7장 실습: 영화 데이터 분석하기
7.1 데이터 불러오기
7.2 데이터 확인하기
|
7장 실습: 영화 데이터 분석하기
7.3 영화 평점과 참여자 수 분석하기
|
6장 데이터 전처리
6.1 결측치 처리하기
6.1.1 결측치 확인하기


- 특정 열의 결측치 확인하기
- gender 열의 결측치 개수 확인

isna() 메서드는 isnull() 메서드와 동일한 기능을 제공

- 여러 열의 겶측치 확인하기

6.1.2 결측치 제거하기
- dropna() 메서드로 결측지 제거하기

DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)- 특정 열에서 결측치가 있는 행 제거하기


- 임계값을 지정해 결측치가 많은 행 제거하기

- axis와 how 매개변수 적용해 결측치 제거하기



- 결측치가 많은 열 제거하기
df.drop(labels=None, axis=0, index=None, columns=None, inplace=False, errors='raise')- errors
- raise(기본값): 지정한 행 또는 열이 없을 경우 오류 발생
- ignore: 지정한 행 또는 열이 없어도 무시
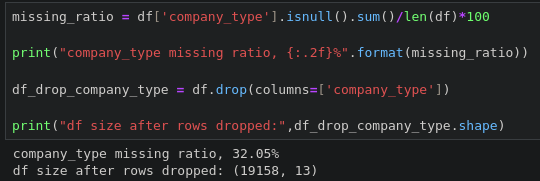
- 문자열 포매팅: {.02f}
- .2: 소수점 이하 둘째 자리까지 표시
- f: 실수(float)로 출력
- %: 형식 지정자가 아닌 문자 그대로 % 기호를 추가
6.1.3 결측치 대체하기
df.fillna(value=None, axis=None, inplace=False, limit=None)
- 단일 값을로 결측치 대체하기

- 열마다 다른 값으로 결측치 대체하기
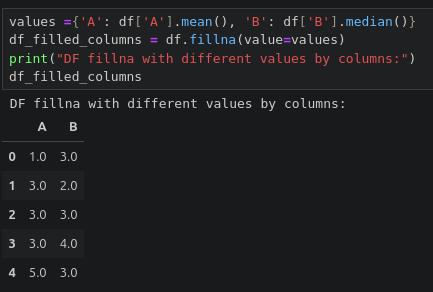
- 횟수를 제한해 열마다 다른 값으로 결측치 대체하기

- 원본 데이터프레임 수정하기

6.1.4 실습: HR Analytics 데에터셋의 결측치 대체하기
- gender 열의 결측치 대체하기

- education_level 열의 결측치 대체하기

- experience 열의 결측치 대체하기

- company_size와 company_type 열의 결측치 대체하기

6.2 데이터 타입 변환하기
6.2.1 데이터 타입 확인하기: dtypes

df.dtypes[열_이름]- Pandas 주요 데이터 타입
- int64: 정수형 데이터
- float64: 실수형(부동 소수점) 데이터
- object: 문자열 또는 범주형 데이터
- datetime64[ns]: 날짜 및 시간 데이터

6.2.2 정수형으로 변환하기
astype(dtype, copy=True, errors='raise')| Pandas 데이터 타입 | astype()에서 사용하는 타입 |
| int64 | int |
| float64 | float |
| object | str |
| datetime64[ns] | datetime64 |

6.2.3 날짜형으로 변환하기
pd.to_datetime(arg, errors='raise')- errors:
- 'coerce': 변환할 수 없는 값은 NaT(결측치)로 처

- errors='coerce'를 설정해 변환할 수 없는 값(예 - '잘못된값')은 NaT로 처리.
- 날짜형 데이터로 변환시 다음 작업을 수월히 할 수 있음
- 특정 날짜 간의 기간을 계산
- 특정 연도, 월, 일에 해당하는 데이터를 빠르게 추출
- 트렌드 분석, 시즌별 변화 등 시간 데이터를 활용한 분석이 용이
6.3 데이터 재구성하기
6.3.1 열 이름 변경하기
DataFrame.rename(index=None, ..., columns=None, axis=None, copy=True,
inplace=False, level=None, errrs='ignore')
6.3.2 새로운 열 만들기

6.3.3 데이터 정렬하기
df.sort_values(by, axis=0, ascending=True, inplace=False, ...)- 단일 열을 기준으로 정렬하기

- 여러 열을 기준으로 정렬하기

- 원본 데이터프레임 수정하기

6.4 데이터 정제하기
6.4.1 중복 데이터 처리하기
df.drop_duplicates(subset=None, keep='first', inplace=False)
6.4.2 이상치 처리하기
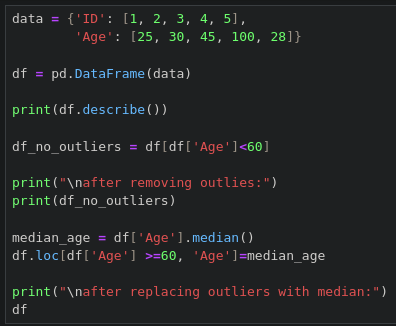
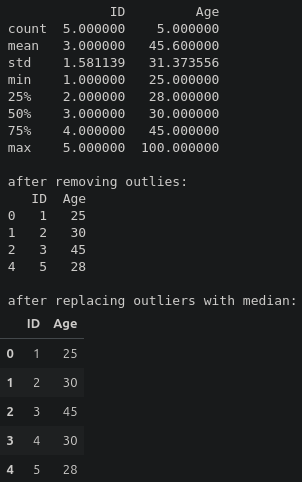
6.4.3 문자열 데이터 정제하기
주요 메서드
- str.strip()

- str.replace(기존_값, 새로운_값)

- str.upper()/str.lower()


- >, < 기호가 포함된 문자열 데이터를 정제해서 숫자형으로 변환하기


- 쉼표가 포함된 문자열 데이터를 정제해서 숫자형으로 변환하기

- % 기호가 포함된 문자열 데이터를 정제해서 숫자형으로 변환하기

6.5 데이터 병합하기
6.5.1 데이터 연결하기
pd.concat(objs, axis=0, join='outer', ignore_index=False, ...)

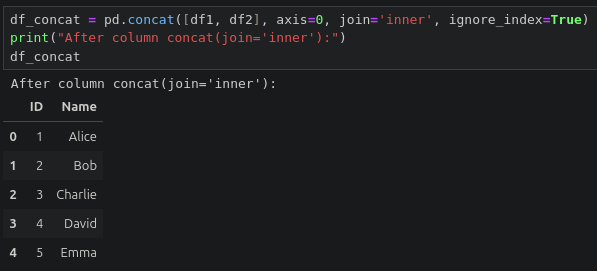
6.5.2 데이터 병합하기
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, suffixes=('_x', '_y'), ...)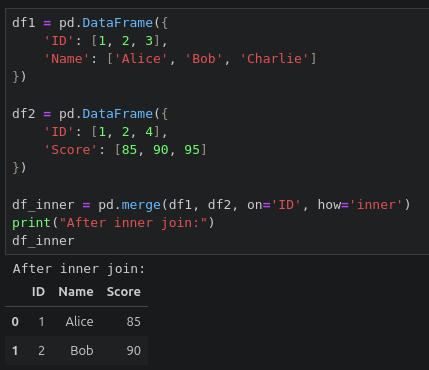



Part 3 데이터 분석과 시각화 실습하기
7장 실습: 영화 데이터 분석하기
7.1 데이터 불러오기

7.2 데이터 확인하기
7.2.1 데이터 구조 파악하기


7.2.2 기본 통계 정보 확인하기

7.2.3 데이터 크기 확인하기

7.3 영화 평점과 참여자 수 분석하기
7.3.1 영화 평점의 평균 구하기

7.3.2 최고 평점 영화 찾기
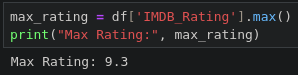

7.3.3 최저 평점 영화 찾기



7.3.4 전체 평가 참여자 수와 영화당 평균 참여자 수 구하기
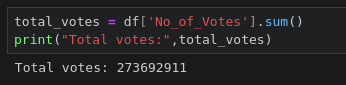

7.3.5 데이터 분석 결과


